CHORUS Forum, “Linking from Datasets to Content,” featured speakers discussing strategies, technologies, and best practices for effectively connecting data to the content it represents.
Referencing a pre-forum poll that collected registrants’ views on the challenges and opportunities of linking datasets to content, moderator Shelley Stall shared some of the most common challenges:
- Simplifying the linking process
- Ensuring robust link maintenance
- Overcoming reticence and lack of awareness
- Addressing cost and logistical efforts
- Social and cultural challenges to uptake and adoption
With regard to opportunities, poll respondents were primarily focused on discoverability and reproducibility — criteria at the very heart of the rationale behind linking datasets and content.
Danie Kinkade, Director of the Biological and Chemical Oceanography Data Management Office at the Woods Hole Oceanographic Institution, spoke about linking information and datasets from the perspective of a repository. Ocean research data are often varied and complex, with a wide array of file types, scales, and formats, and a single collaborative research project could involve several investigators. It is, according to Kinkade, a broad data landscape with some good qualities and some not-so-good qualities.
Kinkade provided a view of the Ocean Research Workflow, giving forum-goers a glimpse at how datasets may go out to various repositories that do not speak to each other — meaning a single research idea gets split up. This shows how complex and broad the ocean research workflow can be:
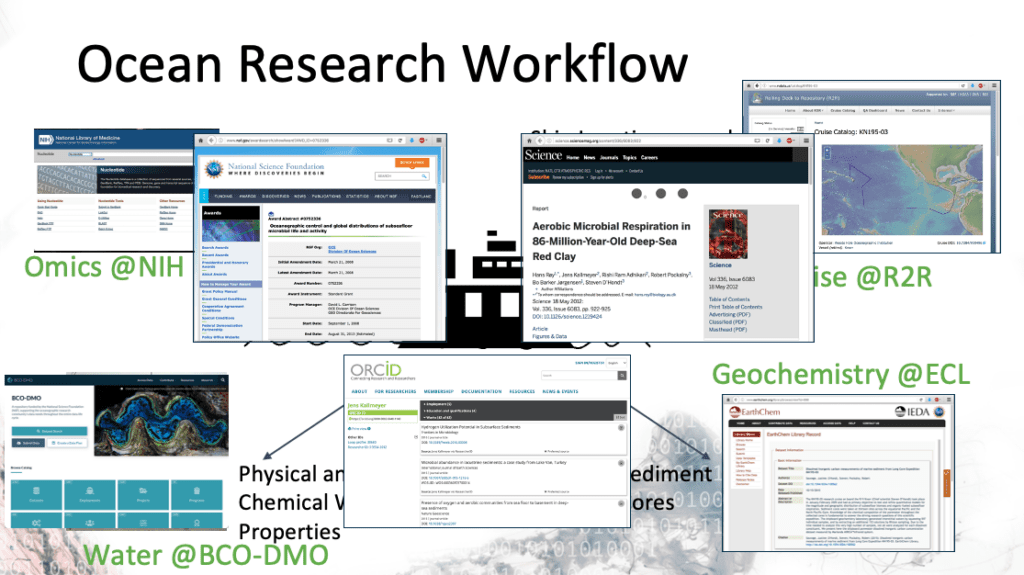
This workflow is difficult for the researcher, but repositories can help by making these connections and leveraging best practices, including:
- Standardizing formats
- Assigning persistent identifiers (PIDs)
- Partnering to provide access
- Sharing related content
- Providing discovery and access to the content related to the repository’s curated datasets
For example, using the power of PIDs, a repository can pull related additional data hosted in a different specialized repository, such as accession numbers, back into itself — providing a more holistic view of the research project and allowing the researcher to discover and access the content sitting in another repository.
One working group at the RDA, “Repo2Pub,” is aimed at streamlining the process of publishing data related to scholarly articles, which is still quite challenging. If you are interested in joining the RDA Working Group please click here (thank you to working group co-chair Natalie Raia for providing that link). Simply log in or create an account and select the “Join Group” button to receive updates (~1 message/month) on working group meetings and activities.
Martin Halbert, Science Advisor for Public Access at NSF, spoke about what the NSF is looking at in terms of complexities, researcher burden, possible applications of AI-directed linking of content with data, and the fact that these issues of alignment are international in scope. The NSF is working on the requirements laid out in the OSTP Nelson Memo, issued by the White House in 2022, as well as its implementation in the annual project reporting processes of the NSF Public Access Repository. “There is an enormous power in linking content with data and capturing the many relationships between content,” said Halbert.
Such complex interlinkages present a number of practical challenges around implementation in agency policies and procedures. Halbert drew attention to two sections regarding the implementation of public access requirements for data and content in the Nelson memo:
- section 3 (2025) requirements to publish full policy development for plans are due to implement by 2025
- section 4 (2026) requirements to complete policy decisions are due by 2026 with implementation by 2027
Martin believes section 4 is more provocative and technically more difficult to implement — but will deliver a great deal of beneficial impact. It should, he noted, be considered as a whole, as it effectively leads to the concept of an end-to-end machine-readable knowledge graph for all scientific articles and data arising from federal research funded awards.
The challenge of recording all this data is it takes a lot of work. There are many questions to consider:
- Who is going to do the work: principle investigators? Awardees? Others?
- What types of training and preparations are available?
- Are the beneficial impacts worth all the extra work?
According to Halbert, NSF is very aware of these issues and concerns, and they are conscious about researcher burden in terms of annual reporting requirements. As a result, NSF is trying to implement the Nelson memo in ways that are fair and effective.
The agency is also considering whether AI tools can be used to create and surface data/content linkages. The ramifications of doing so have to be considered, as errors will be injected — so what error level is acceptable? If AI is not used, who and how will the relationships be connected? Halbert noted that, to be effective, these kinds of scenarios will require cultivating an emerging consensus of practices in the global scientific community, which is no trivial task.
DataCite Executive Director Matt Buys discussed connecting research leads to advancing knowledge, noting that by making more research and resources openly discoverable, reusable, and available to the larger community, we will bring rigor to the scholarly record and advance knowledge. Over the past decade there has been great progress made in data sharing, with national and funder policies offering support, raising awareness, and establishing infrastructure to bolster preservation, citation, and controlled access. Buys shared there is more need for broad discoverability and research assessment, as there is still a heavy focus on publications — and few including data. As a community, we need to cultivate change to make it easy and rewarding to share. The image below from Buys’s presentation shows the steps necessary to cultivate and influence a change:
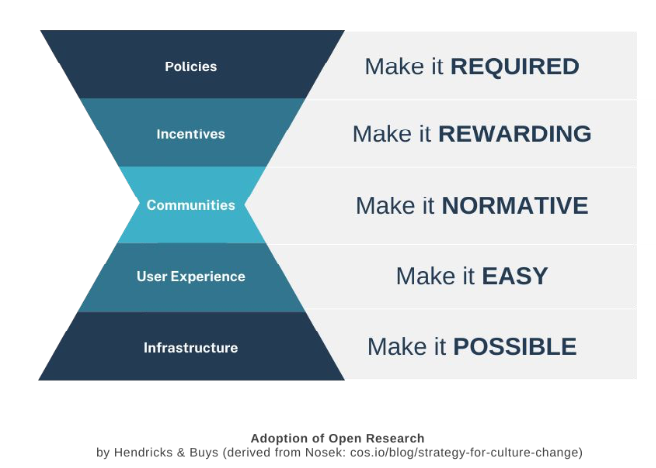
Influencing change among researchers is necessary, as many still perceive the process as a burden with little reward. Supporting researchers by linking datasets with research objects is starting to resonate with researchers as a value.
Important initiatives doing work in this area include Make Data Count — which is building open infrastructure and community-based standards, advocating through outreach and adoption, and performing evidence-based bibliometric studies — and Data Citation Corpus, which brings together data citations from metadata and third-party sources.
Buys believes that, in addition to building on existing infrastructure, the immediate priorities are:
- No longer focusing on altering publisher behavior
- Allowing and encouraging repositories to add citation links to dataset metadata
- Using text mining and Natural Learning Processing (NLP) to expedite surfacing data citations
- Leverage open metadata, persistent identifiers, aggregate linkages not exposed in open sources
Be sure to listen to the Q&A session, where the panel further discussed issues around linking datasets to content and the challenges in doing so.
Links to the speaker presentations and recordings can be found on the event page.
Links shared on chat during the event:
Doug Schuster: A paper describing NASA work relevant to this discussion: Gerasimov, I., Savtchenko, A., Alfred, J., Acker, J., Wei, J. and Binita, K. (2024) ‘Bridging the Gap: Enhancing Prominence and Provenance of NASA Datasets in Research Publications’, Data Science Journal, 23(1), p. 1. Available at: https://doi.org/10.5334/dsj-2024-001.
Doug also shared: “Characteristics of Raw Observations”: http://n2t.net/ark:/85065/d7rf607v which came up during an internal exercise to define commonalities across the various “domain repositories” at NCAR.
CHORUS is incredibly thankful to our sponsors of this event and their continued support of CHORUS, our community, and discussions around important issues the community faces.